


L'intégration de l'IA dans les systèmes existants peut s'avérer complexe, mais elle offre un immense potentiel d'amélioration de l'efficacité et de réduction des coûts. De nombreuses entreprises s'appuient sur des systèmes obsolètes, dont certains datent de plus de 20 ans, qui manquent souvent de la souplesse nécessaire pour intégrer l'IA. Cependant, avec une approche adaptée, les entreprises peuvent surmonter ces obstacles et réaliser des gains tangibles. En voici un bref aperçu :
- Audit du système: évaluer la compatibilité du matériel, des logiciels et des données.
- Objectifs commerciaux: définir des objectifs clairs et suivre les progrès à l'aide d'indicateurs de performance clés (KPI) mesurables.
- Gouvernance des données: normaliser, nettoyer et sécuriser les données pour garantir la fiabilité des résultats de l'IA.
- Stratégies d'intégration: utilisez des API, des intergiciels et des méthodes incrémentales telles que le modèle « Strangler Fig » pour moderniser vos systèmes en toute sécurité.
- Sécurité et fiabilité: recourir au chiffrement, aux contrôles d'accès et aux mécanismes de sécurité intégrée pour protéger et stabiliser les systèmes.
- Déploiement progressif: mettez en place l'IA progressivement en prévoyant des tests, un suivi et des plans de retour en arrière.
Des exemples concrets, comme le système de détection des fraudes de HSBC, montrent comment l'intégration de l'IA peut doubler l'efficacité tout en réduisant les erreurs. Pour réussir, il faut mettre l'accent sur la préparation, la compatibilité technique et une gouvernance solide. Des événements tels que le RAISE Summit 2026 à Paris offrent des perspectives et des occasions de réseautage aux professionnels confrontés aux défis liés à l'intégration de l'IA.
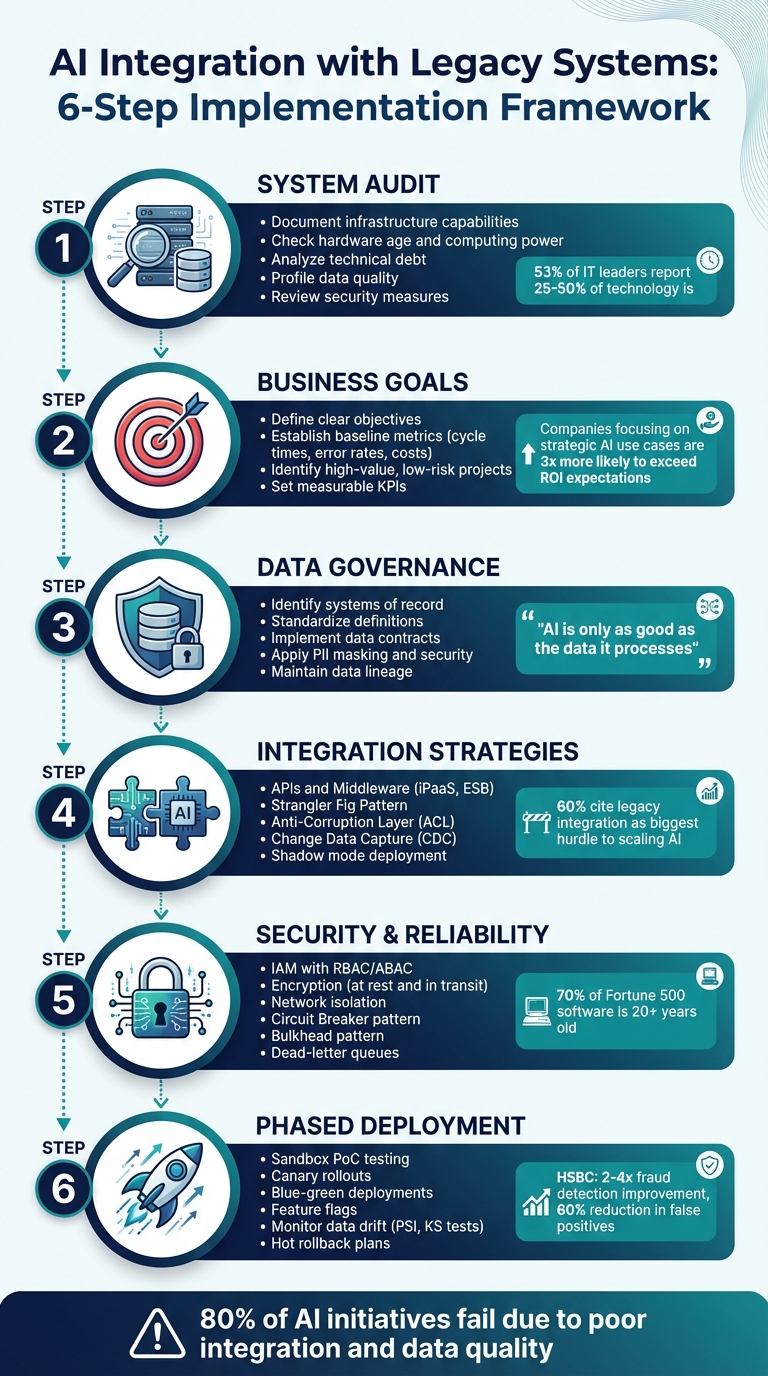
Intégration de l'IA aux systèmes existants : cadre de mise en œuvre en 6 étapes
Les défis liés à l'intégration de l'IA dans les systèmes existants | Cours exclusif
sbb-itb-e314c3b
Liste de contrôle : se préparer à l'intégration
Pour relever les défis liés à l'intégration, il faut commencer par un examen approfondi de vos systèmes existants. Une préparation minutieuse permet d'éviter des erreurs coûteuses et garantit que votre intégration s'aligne sur vos objectifs commerciaux. Voici une liste de contrôle pour vous guider à travers les étapes essentielles d'un déploiement réussi de l'IA.
Réaliser un audit complet du système
Commencez par réaliser un audit de vos systèmes existants. Répertoriez les capacités de votre infrastructure afin d'identifier les fonctionnalités compatibles avec l'IA et les domaines à améliorer [6]. Vérifiez l'âge du matériel, la puissance de calcul et la compatibilité avec les solutions cloud. Déterminez si votre système est monolithique ou s'il prend en charge des fonctionnalités modernes telles que les API à faible latence et l'inférence en temps réel [4].
Ne négligez pas l'analyse de la dette technique. Un code obsolète, des correctifs personnalisés et une architecture fragile peuvent compliquer les mises à niveau [6]. Identifiez les dépendances et les goulots d'étranglement susceptibles d'entraver la compatibilité avec les outils d'IA [2]. Évaluez également la capacité de votre équipe à gérer des langages de programmation hérités tels que COBOL parallèlement à des plateformes d'IA plus récentes et natives du cloud [4].
Accordez une attention particulière au profilage des données. Vérifiez que vos données ne contiennent pas de valeurs manquantes, d'incohérences ou de redondances [2][4]. Vérifiez vos mesures de sécurité pour vous assurer qu'elles répondent aux normes actuelles, telles que le chiffrement, l'authentification multifactorielle et la conformité au RGPD [6][2]. Gardez à l'esprit que 53 % des responsables informatiques indiquent qu'une part importante (25 % à 50 %) de leurs technologies est considérée comme obsolète [3].
Définir des objectifs commerciaux clairs
Les projets d'intégration échouent souvent lorsque la technologie prime sur les besoins de l'entreprise [9]. Avant de choisir des outils ou des plateformes, concentrez-vous sur la définition de la raison d’être de votre intégration. Identifiez les flux de travail spécifiques dans lesquels l’IA peut apporter des améliorations mesurables. Établissez rapidement des références: suivez les durées de cycle, les taux d’erreur et les coûts actuels au cours des deux premières semaines afin de créer un repère clair pour évaluer les progrès [10].
Évaluez les opportunités offertes par l'IA en mettant en balance leur valeur potentielle et les efforts nécessaires à leur mise en œuvre. Commencer par des projets à faible risque et à fort rendement peut créer une dynamique et permettre d'obtenir des résultats rapides [11]. Des études montrent que les entreprises qui se concentrent sur des cas d'utilisation stratégiques de l'IA ont près de trois fois plus de chances de dépasser leurs attentes en matière de retour sur investissement [11]. De plus, les organisations dans lesquelles les équipes d'IA contribuent à définir les indicateurs de réussite ont 50 % plus de chances d'utiliser efficacement l'IA [11].
Définir clairement les flux de travail qui doivent rester stables, les exigences réglementaires à respecter et les créneaux opérationnels (tels que les délais de traitement par lots) qui ne doivent pas être perturbés pendant l'intégration [9]. Choisissez un petit ensemble d'indicateurs pour surveiller à la fois les risques et les avantages, tels que la latence des transactions pendant l'intégration et le temps de récupération après des erreurs [9].
Une fois les objectifs commerciaux clairement définis, mettez en place des pratiques rigoureuses en matière de gouvernance des données afin de garantir la fiabilité des informations.
Mettre en place la gouvernance des données
Une gouvernance rigoureuse des données est la clé d'une intégration réussie de l'IA. Commencez par identifier les systèmes de référence: déterminez quel système existant gère des champs de données spécifiques afin d'éviter tout conflit lors de la synchronisation [9]. Créez des définitions standardisées pour les termes clés tels que « client » ou « commande » afin d'harmoniser les pratiques en matière de données entre les anciens et les nouveaux systèmes [9][10].
Mettre en place des contrats de données qui définissent quels attributs de données font autorité et lesquels sont complémentaires, afin de garantir que les modèles d'IA s'appuient sur des informations fiables [10]. Utilisez des mesures de sécurité granulaires, telles que le masquage des informations personnelles identifiables (PII) et la sécurité au niveau des lignes, pour protéger les données sensibles et respecter les normes de conformité telles que le RGPD [10]. Assurez la traçabilité des données afin de suivre leur parcours depuis leur source jusqu'aux résultats de l'IA, rendant ainsi chaque décision traçable et vérifiable [10].
« L'IA n'est efficace que dans la mesure où les données qu'elle traite le sont. »
– Mila Rowe, rédactrice spécialisée en technologie, Kovair [2]
Effectuez un contrôle de la qualité des données dès le début du processus. Recherchez les enregistrements en double, les clés manquantes et les incohérences dans les codes avant de lancer l'intégration [9]. Pour éviter que des données obsolètes n'affectent les modèles d'IA, envisagez de mettre en place une couche anti-corruption, c'est-à-dire un outil qui convertit les données héritées en formats compatibles avec les systèmes d'IA modernes [9]. Enfin, établissez des règles claires pour résoudre les conflits d'écriture lorsque le système existant et la plateforme d'IA tentent tous deux de mettre à jour le même enregistrement [9].
Liste de contrôle des stratégies d'intégration : connexion des systèmes existants et de l'IA
Une fois vos systèmes audités et vos objectifs commerciaux clairement définis, l'étape suivante consiste à relever le défi de l'interconnexion des systèmes existants avec l'IA. Pour de nombreuses entreprises, ce n'est pas une mince affaire : plus de 60 % d'entre elles citent « l'intégration avec les systèmes existants » comme le principal obstacle à la mise à l'échelle de l'IA [5]. Le recours à des méthodes d'intégration éprouvées peut aider l'IA à améliorer les anciens systèmes tout en limitant au maximum les perturbations.
Utiliser les API et les intergiciels
Les API et les intergiciels font office de passerelles entre les systèmes existants et les solutions d'IA modernes. Des outils tels que les passerelles API et les façades permettent d'uniformiser l'accès, d'appliquer les protocoles de sécurité et de gérer le trafic afin d'éviter que les requêtes d'IA ne surchargent le matériel obsolète [5]. Pour les organisations qui jonglent avec plusieurs systèmes, des plateformes telles que les plateformes d'intégration en tant que service (iPaaS) et les bus de services d'entreprise (ESB) centralisent l'orchestration, facilitant ainsi l'acheminement des requêtes et la gestion de la transformation des données entre différentes plateformes [5].
Pour les systèmes dépourvus d'interfaces programmables, l'automatisation robotisée des processus (RPA) peut constituer une solution temporaire. La RPA imite les actions de l'utilisateur pour extraire ou saisir des données via les interfaces existantes, offrant ainsi une solution rapide mais à court terme. Il faut toutefois garder à l'esprit que la RPA nécessite une maintenance continue. Pour les opérations en temps réel, envisagez une architecture orientée événements avec des outils tels qu'Apache Kafka. Cette approche permet à l'IA de réagir à des déclencheurs système sans créer de dépendances rigides vis-à-vis de systèmes hérités fragiles [5].
Le secteur bancaire en est un excellent exemple : grâce aux intergiciels, il est possible de collecter des données en temps réel pour la détection des fraudes par l'IA, ce qui montre comment de telles stratégies peuvent fonctionner dans des environnements où les enjeux sont considérables [3].
Appliquer des modèles de modernisation progressive
Une modernisation progressive est souvent plus sûre qu'une refonte complète en une seule fois. Le modèle « Strangler Fig » est l'une de ces méthodes. Il consiste à intercepter les requêtes du système et à les rediriger vers de nouveaux services basés sur l'IA, tout en laissant l'ancien système fonctionner en parallèle [13][14]. Cette approche garantit la continuité des fonctionnalités pendant la transition.
« Le modèle Strangler Fig offre une approche contrôlée et progressive de la modernisation. Il permet à l'application existante de continuer à fonctionner pendant le processus de modernisation. »
– Microsoft Azure [14]
Une autre stratégie utile est la couche anti-corruption (ACL). Cette méthode intègre les systèmes existants dans une couche API moderne, en convertissant les protocoles obsolètes tels que SOAP ou COBOL en formats comme REST/JSON que les outils d'IA peuvent utiliser [15][8]. Cela s'avère particulièrement avantageux pour les systèmes trop critiques pour être remplacés, comme les plateformes bancaires centrales, car cela évite de modifier le code d'origine [4].
Vous pouvez également commencer par un déploiement en mode « shadow », dans lequel l'IA fonctionne en parallèle des systèmes existants afin de valider sa précision avant de prendre le relais. Par exemple, le Valley Medical Centre a utilisé l'outil d'IA Xsolis Dragonfly de cette manière, ce qui a permis d'augmenter le nombre d'observations cliniques (de 4 % à 13 %) et d'améliorer l'efficacité du personnel grâce à l'automatisation des examens manuels [3].
Ces méthodes permettent une mise à niveau plus fluide des fonctionnalités existantes, créant ainsi une base solide pour l'intégration future de l'IA.
Améliorer l'intégration au niveau des données
L'intégration des données est un autre élément clé du puzzle. Les outils de capture des données modifiées (CDC) répliquent les données des systèmes existants en temps réel sans modifier la base de données d'origine [5][4]. Cela s’avère particulièrement utile lorsque les systèmes existants ne peuvent pas supporter la charge supplémentaire générée par les requêtes d’IA. La virtualisation des données permet quant à elle aux modèles d’IA d’accéder aux données existantes sans les déplacer, en utilisant des couches de fédération pour créer une vue unifiée [5].
Pour les systèmes qui ne prennent pas en charge la diffusion en continu en temps réel, le micro-batching offre un compromis en simulant des mises à jour en temps quasi réel [5]. L'ajout d'une mise en cache peut également accélérer l'accès aux données héritées critiques [5]. Pour garantir la qualité des données – un obstacle courant dans les projets d'IA –, automatisez les processus de nettoyage des données afin de normaliser les formats et de traiter les valeurs manquantes. La mauvaise qualité des données est responsable de 80 % des retards dans les projets d'IA [12]. De plus, établissez des règles claires pour la synchronisation des données lorsque le système existant et la plateforme d'IA doivent mettre à jour les mêmes champs [9].
Liste de contrôle relative à la sécurité et à la fiabilité : protéger votre intégration
Il est essentiel de garantir la sécurité et la fiabilité de la connexion de votre système d'IA existant. L'Australian Signals Directorate insiste sur ce point en déclarant : « Les systèmes d'IA sont des systèmes logiciels. À ce titre, les organisations qui les déploient devraient privilégier les systèmes sécurisés dès leur conception, dans lesquels le concepteur et le développeur du système d'IA s'intéressent activement aux résultats positifs en matière de sécurité une fois le système en service » [19]. Une approche globale garantit que votre intégration reste stable et protégée, en s'appuyant sur des stratégies antérieures pour assurer le bon déroulement des opérations.
Mettre en place des mesures de sécurité
Pour sécuriser votre intégration, commencez par mettre en place une gestion des identités et des accès (IAM) avec un contrôle d'accès basé sur les rôles (RBAC) ou un contrôle d'accès basé sur les attributs (ABAC) afin de limiter l'accès aux données sensibles [16][17][18]. Évitez les identifiants codés en dur : utilisez des identités gérées pour une authentification sécurisée entre les composants d'IA et les systèmes existants [16].
Chiffrez les données au repos et en transit à l'aide de normes modernes telles que HTTPS et TLS. De plus, isolez les réseaux à l'aide de réseaux virtuels (VNets), de liaisons privées et d'enclaves dédiées [16][17][19]. Pour les flux de travail traitant des informations sensibles, déployez des outils de prévention des pertes de données (DLP) afin de détecter et de masquer les données sensibles [16]. Protégez les poids des modèles, les points de contrôle et les configurations dans des environnements sécurisés afin d'empêcher tout accès non autorisé ou toute altération [18][19].
Adoptez le principe du « refus par défaut » en bloquant tous les appels externes et tous les accès au réseau, sauf s'ils sont explicitement autorisés via des listes d'autorisation [18][19]. Pour des opérations telles que le déploiement de modèles ou l'accès aux poids des modèles, utilisez le protocole TPI (Two-Person Integrity), qui exige l'autorisation de plusieurs parties pour les actions sensibles [18][19].
Exécutez l'IA et les intergiciels dans des conteneurs isolés et sécurisés afin de minimiser les risques liés à d'éventuelles failles [18][19]. Renforcez les API exposées à l'aide d'une authentification robuste, d'une limitation de débit et d'une validation de schéma afin d'éviter des problèmes tels que l'inversion de modèle ou l'extraction non autorisée de données [18][19]. Conserver des journaux détaillés des invites, des résultats et des appels d'outils afin de faciliter les enquêtes judiciaires et la réponse aux incidents [18].
Améliorer la fiabilité du système
Les mesures de sécurité protègent vos données, mais c'est la fiabilité qui garantit le bon fonctionnement de votre système. Sachant que 70 % des logiciels utilisés par les entreprises du classement Fortune 500 ont plus de 20 ans [3], la résilience est essentielle. Utilisez le modèle « Circuit Breaker » pour éviter les défaillances en cascade : si le système d'IA présente des dysfonctionnements ou si le système existant est surchargé, le circuit se coupe pour maintenir la stabilité [15][20]. De même, appliquez le modèle Bulkhead pour isoler les défaillances au sein de composants spécifiques, empêchant ainsi les problèmes de se propager à l'ensemble du système [17].
Pour éviter les doublons ou les surcharges, assurez-vous que les écritures sont idempotentes et utilisez des tentatives de réessai avec délai d'attente exponentiel [15][9]. Acheminez les messages ayant échoué vers une file d'attente de messages perdus pour un examen manuel ou une relecture automatisée, en veillant à ce qu'aucune donnée ne soit perdue en cas de défaillance [9][10].
Surveillez l'état du système en suivant les identifiants de corrélation, la latence et les taux d'erreur sur l'ensemble du parcours d'intégration, de l'agent IA au système existant [15][9]. Répartissez les services d'IA sur plusieurs régions afin de maintenir la disponibilité en cas de pannes régionales ou de limites de quota [20]. Des outils tels que la gestion des API ou les passerelles d'application peuvent automatiquement répartir les requêtes vers des instances opérationnelles et gérer les basculements [20][22]. Configurez des alertes pour les activités inhabituelles telles que les entrées malveillantes, la dérive des données ou les actions répétitives à haute fréquence pouvant signaler une violation [19].
Plan pour des déploiements résilients
Les stratégies de déploiement sont essentielles pour réduire au minimum les perturbations. Optez pour des déploiements « bleu-vert », qui reposent sur deux environnements identiques – l'un en production et l'autre mis à jour –, ce qui permet des retours en arrière rapides et des temps d'arrêt minimaux [21]. Les déploiements progressifs de type « canary » transfèrent une petite partie du trafic vers la nouvelle intégration, réduisant ainsi le risque de problèmes généralisés [21].
Testez l'IA en mode fantôme pour vérifier sa précision sans affecter votre système existant [15][10]. Les indicateurs de fonctionnalité vous permettent d'activer ou de désactiver les capacités de l'IA sans redéployer le système [10]. Préparez-vous aux situations d'urgence grâce à des plans de « hot rollback » qui désactivent instantanément les canaux d'IA et utilisent des transactions compensatoires pour annuler les modifications problématiques [15].
Réaliser une analyse des modes de défaillance (FMA) afin d'identifier les points de défaillance potentiels, tels que les délais d'attente réseau ou les interruptions de service, et définir des réponses automatisées telles que les tentatives de reconnexion ou les basculements [20]. Enfin, automatisez les tests de charge à l'aide d'outils tels qu'Azure Load Testing afin d'identifier les goulots d'étranglement et de valider les mécanismes de basculement avant la mise en production [10].
Liste de contrôle pour le déploiement et la surveillance : mise à l'échelle de l'IA en production
Une fois les mesures de sécurité et de fiabilité mises en place, l'étape suivante consiste à déployer efficacement l'IA et à surveiller ses performances. Sachant que plus de 80 % des initiatives en matière d'IA échouent en raison d'une intégration défaillante et de problèmes liés à la qualité des données [23], il est indispensable de disposer d'une stratégie de déploiement structurée.
Suivre un plan de déploiement par étapes
Commencez par documenter votre architecture et par identifier les points d'intégration à faible risque. Avant de vous lancer dans un déploiement à grande échelle, testez les modèles d'intégration et évaluez l'impact sur l'activité à l'aide d'une démonstration de faisabilité (PoC) en environnement de test.
Prenons l'exemple de HSBC. En collaboration avec Google Cloud, la banque a mis en place un système de détection des fraudes basé sur l'IA, capable d'analyser 900 millions de transactions par mois. En déployant ce système par étapes, elle a multiplié par deux à quatre le taux de détection des fraudes tout en réduisant les faux positifs de 60 % [3].
Les déploiements progressifs tirent souvent parti de techniques telles que les déploiements « canary », dans le cadre desquels les nouvelles fonctionnalités sont d'abord introduites dans certaines régions ou auprès de certains groupes d'utilisateurs. De cette manière, les éventuels problèmes sont circonscrits sans affecter la majorité des utilisateurs.
Par exemple, une entreprise du secteur pétrolier et gazier a intégré une couche de requêtes basée sur l'IA générative à un tableau de bord d'équipements existant. Cette couche synthétisait les alertes provenant de plus de 1 000 capteurs IoT. Avant de déployer le système à grande échelle, l'entreprise a mené une démonstration de faisabilité (PoC) de six mois portant sur 20 machines, ce qui lui a permis d'éviter avec succès des pannes imprévues et coûteuses [24].
Définissez des critères de qualité clairs, c'est-à-dire des seuils de performance que les modèles doivent respecter avant de passer de la phase de développement à celle des tests, puis à la mise en production. De plus, concevez des systèmes dotés de mécanismes de sécurité permettant de revenir à une logique traditionnelle si le service d'IA tombe en panne ou produit des résultats erronés.
Une fois que le déploiement progressif aura confirmé la fiabilité du système, veillez à assurer la rétrocompatibilité afin de garantir le bon fonctionnement du système.
Préserver la compatibilité ascendante
La rétrocompatibilité est essentielle pour une intégration transparente de l'IA. Les indicateurs de fonctionnalité vous permettent de contrôler le déploiement de l'IA et de désactiver rapidement certaines fonctionnalités en cas de baisse des performances. Utilisez des passerelles API pour gérer la conversion de protocoles — par exemple, en convertissant les requêtes JSON en chaînes de caractères à largeur fixe pour les systèmes hérités — tout en appliquant les normes de sécurité modernes aux points de terminaison plus anciens.
La gestion des versions est une autre pratique essentielle. Gérez les versions de votre code, de vos modèles et de vos ensembles de données afin de faciliter les mises à niveau et les retours en arrière. Pour les systèmes existants, intégrez les fonctionnalités dans une couche API contrôlée. Cela permet d'uniformiser les interactions et de faire respecter les contrats, ce qui permet au système central de rester inchangé à mesure que les composants d'IA évoluent.
Pour les systèmes d'IA disposant d'un accès en écriture, mettez en place des transactions compensatoires déterministes et vérifiables afin d'annuler toute action problématique dans les environnements de production. Ces mesures de précaution garantissent la continuité opérationnelle pendant que vous mettez en place une surveillance robuste.
Définir des normes en matière de gouvernance et de surveillance
La gouvernance doit être mise en place dès le début, dès la phase de collecte des cas d'utilisation. Il convient d'attribuer des niveaux de risque en fonction de l'impact potentiel sur l'activité et d'exiger la mise à disposition des éléments indispensables – tels que les schémas d'entrée/sortie, les données d'entraînement, les données de référence et les configurations de test des métriques – avant de passer à l'étape suivante. Des suites de tests automatisées peuvent ensuite vérifier la stabilité, la dérive des données et la dérive conceptuelle avant que tout instantané de modèle ne soit déployé en production.
Utilisez des indicateurs tels que PSI, les tests KS et la divergence de Jensen-Shannon pour surveiller les dérives au niveau des données, des performances et de la sécurité. Harmonisez les outils entre les équipes en définissant des SDK et des API cohérents, ce qui permet de réduire les problèmes de compatibilité et d'accélérer les cycles de développement. Configurez les systèmes pour qu'ils intègrent automatiquement des outils de surveillance des performances et des dérives en fonction du type de modèle avant le déploiement. De plus, veillez à ce que le personnel d'astreinte dispose d'un accès à des procédures simplifiées permettant de désactiver d'un simple clic des chemins, des outils ou des modèles spécifiques en cas de problèmes de sécurité ou de performances.
Ces pratiques jettent des bases solides pour déployer efficacement les systèmes d'IA et garantir leur fiabilité, dans le cadre de réflexions stratégiques plus larges menées lors d'événements tels que le sommet RAISE.
Sommet RAISE: découvrir l'intégration de l'IA auprès d'experts du secteur

L'intégration de l'IA dans les systèmes existants ne se résume pas à une simple question de technologie : il s'agit avant tout de bénéficier d'un accompagnement adapté. Le RAISE Summit 2026 (8-9 juillet, Paris) devrait accueillir plus de 9 000 participants et plus de 350 intervenants, tous alignés sur son cadre « 4F Compass » : Foundation, Frontier, Friction et Future [25][27].
Séances consacrées à la stratégie en matière d'IA lors du sommet RAISE
Le Frontier Track explore en détail les enjeux liés à la mise en œuvre de l'IA, du concept à la réalité. Des sessions telles que « Cadres d'adoption de l'IA : des projets pilotes à la mise en production » et « Les données : la colonne vertébrale de l'architecture IA d'entreprise » visent à faire le lien entre les technologies d'IA de pointe et les infrastructures existantes [27]. De son côté, le Friction Track s'attaque aux questions épineuses : des sessions telles que « Le dilemme du retour sur investissement » et « Le défi de la cyber-résilience » abordent les obstacles financiers et sécuritaires liés à la modernisation des systèmes hérités [27].
Pour les dirigeants chargés de la mise en œuvre à grande échelle de l'IA, le CxO Summit offre un espace pour explorer des stratégies de haut niveau en matière d'intégration organisationnelle [26]. Des personnalités de premier plan du secteur, telles que Vishal Talwar (FedEx), Philippe Rambach (Schneider Electric) et Amit Zavery (ServiceNow), partageront leurs expériences [25][28]. Le 8 juillet 2026, David Flynn, PDG de Hammerspace, prendra la parole sur la scène principale pour aborder le thème « Des données prêtes pour l'IA, partout », en mettant l'accent sur la suppression des silos de données afin de rationaliser l'infrastructure de l'IA [30]. Ces sessions sont conçues pour susciter des idées et déboucher sur des opportunités de réseautage fructueuses.
Opportunités de réseautage pour les professionnels de l'intégration de l'IA
Le RAISE Summit est un rendez-vous incontournable pour les décideurs : environ 80 % des participants sont des cadres supérieurs ou des fondateurs. Cela signifie un accès direct à ceux qui gèrent les budgets, supervisent les infrastructures et s'y retrouvent dans les cadres réglementaires [25][26]. La Semaine des événements parallèles propose des dîners, des ateliers et des rencontres exclusifs visant à résoudre des défis tels que les silos de données et l'interopérabilité des systèmes [25].
« À mesure que le monde devient de plus en plus virtuel, je pense qu’il est de plus en plus important que les gens se réunissent. Les rencontres fortuites qui peuvent se produire lorsque l’on se retrouve dans un espace physique peuvent changer le cours d’une vie. » - Chamath Palihapitiya, cofondateur de Social Capital [29]
Le 7 juillet 2026, le MACHINA se penchera sur les interactions entre l'IA, la robotique, les équipements autonomes et d'autres systèmes physiques. Cet événement revêt un intérêt particulier pour les professionnels des secteurs manufacturier et industriel [26]. Les participants pourront également se rendre sur des stands tels que celui de Hammerspace (stand 3B) pour discuter de solutions visant à éliminer les silos de données, ce qui est essentiel pour une intégration transparente de l'IA [30].
Avantages pour les participants et options de billets
Le sommet RAISE fournit aux participants des outils et des stratégies pratiques pour intégrer l'IA dans les systèmes existants.
| Plan | Prix (hors TVA) | Caractéristiques principales |
|---|---|---|
| PRO | €999,00 | Accès au sommet, au salon, aux conférences, aux ateliers, à l'application de réseautage et aux présentations de start-ups |
| VIP | €1 899,00 | Comprend l'accès au salon VIP, des expériences sur mesure et toutes les fonctionnalités PRO |
| VIP MAX | €3 499,00 | Ajoute un dîner exclusif à Paris à tous les avantages VIP et PRO |
L'événement propose également un concours de start-ups doté d'une cagnotte de 5 millions d'euros et un hackathon mondial sur l'IA offrant 200 000 euros de prix, mettant en avant des solutions innovantes pour l'intégration de l'IA [25]. Les billets en prévente sont désormais disponibles pour cet événement incontournable de juillet 2026 [25].
Conclusion : les éléments clés pour une intégration réussie de l'IA
L'importance de la préparation
Préparer le terrain pour l'intégration de l'IA n'est pas seulement utile : c'est absolument indispensable. Comme nous l'avons évoqué dans les listes de contrôle relatives à la préparation et à l'intégration, il est essentiel de commencer par un audit approfondi du système et de mettre en place des pratiques rigoureuses de gouvernance des données. Définir clairement les objectifs métier et établir des indicateurs de performance clés (KPI) mesurables — tels que la précision, la latence et le retour sur investissement — permet de concentrer les efforts sur des cas d'utilisation à fort impact et à faible risque. Selon Gartner, d'ici fin 2026, 60 % des initiatives d'IA échoueront si les données de base ne sont pas correctement préparées [1]. Ces statistiques soulignent l'importance de la préparation en tant que pierre angulaire de la réussite de l'IA.
Résumé des bonnes pratiques techniques et de sécurité
Il est primordial de préserver l'agilité technique et la sécurité lors de l'intégration de l'IA dans les systèmes existants. Des stratégies telles que la modernisation progressive, notamment le recours au modèle « Strangler », permettent aux entreprises de remplacer progressivement les composants obsolètes sans perturber les opérations. L'encapsulation des fonctions stables dans des API garantit que les anciens systèmes peuvent fonctionner en parfaite harmonie avec l'IA, tandis que les intergiciels et les files d'attente de messages aident à gérer les processus plus lents des systèmes existants sans créer de goulots d'étranglement.
La sécurité, bien sûr, ne peut pas être une considération secondaire. Dès le départ, il convient de mettre en place un chiffrement des données au repos et en transit, des contrôles d'accès basés sur les rôles et une authentification multifactorielle. Tester l'IA en mode « shadow » est une autre initiative judicieuse : cela permet aux organisations de valider les résultats de l'IA sans mettre en péril les opérations en production.
« L'intégration de l'IA dans les systèmes existants figure parmi les défis et les opportunités majeurs auxquels sont confrontés les DSI aujourd'hui. » – Michael Fauscette, fondateur, PDG et analyste en chef chez Arion Research [7]
Associées aux étapes préparatoires précédentes, ces mesures techniques et de sécurité constituent un cadre permettant un déploiement fiable de l'IA.
Continuer à se former et à élargir son réseau
L'intégration de l'IA n'est pas une tâche ponctuelle ; il s'agit d'un processus continu qui évolue au rythme des avancées technologiques. Il est essentiel de se tenir informé des nouvelles tendances, telles que l'IA générative et l'IA agentique, pour rester compétitif. Le perfectionnement des équipes qui possèdent déjà une expérience des systèmes existants constitue un autre facteur clé : cela garantit non seulement le bon fonctionnement des opérations d'IA, mais permet également de préserver le savoir-faire institutionnel qui, sans cela, risquerait d'être perdu.
Le réseautage joue également un rôle important pour éviter des erreurs coûteuses. Entre 60 % et 80 % des budgets consacrés aux projets d'IA sont souvent consacrés à l'intégration plutôt qu'au développement [8], ce qui montre clairement que tirer les leçons de l'expérience des autres permet d'économiser à la fois du temps et de l'argent. Des événements tels que le RAISE Summit (8-9 juillet 2026, Paris) offrent une excellente occasion de rencontrer des leaders du secteur et d'acquérir des connaissances pratiques sur l'intégration de l'IA. Ces rencontres sont particulièrement précieuses pour les professionnels confrontés aux complexités de la fusion de l'IA avec les infrastructures existantes.
FAQ
Quel est le premier cas d'utilisation de l'IA le plus sûr pour un système existant ?
Lorsqu'on intègre l'IA dans un système existant, le meilleur point de départ consiste à automatiser les tâches routinières à l'aide de l'IA. Cette approche présente peu de risques et s'avère très pratique. Commencez par des mises en œuvre à petite échelle, comme des projets pilotes ou des produits minimums viables (PMV). Ces étapes progressives permettent d'assurer une intégration en douceur, de réduire les perturbations et de tester la compatibilité avec les systèmes existants. C'est une méthode prudente mais efficace pour évaluer les performances et apporter les ajustements nécessaires.
Comment intégrer l'IA sans réécrire la plateforme principale ?
Pour intégrer l'IA à votre système sans avoir à remanier votre plateforme principale, envisagez des solutions non intrusives telles que la capture des données modifiées (CDC), les surveillants de fichiers ou les intergiciels. Ces outils permettent de reproduire les données et les interfaces de votre système existant, ce qui facilite l'intégration.
L'utilisation de couches découplées – telles que des API ou des files d'attente de messages – permet de maintenir les composants d'IA séparés du système principal, réduisant ainsi le risque d'interférence. Lors des tests, l'exécution en parallèle des processus d'IA garantit la stabilité du système pendant que l'IA traite des données en temps réel. Cette approche vous permet d'intégrer efficacement l'IA sans perturber votre architecture existante.
Comment garantir la sécurité, la conformité et la traçabilité des résultats générés par l'IA ?
Pour garantir la sécurité, la conformité et la traçabilité des résultats générés par l'IA, il est essentiel de mettre en œuvre des mesures de sécurité adaptées à chaque étape du cycle de vie de l'IA. Cela implique de sécuriser les environnements d'entraînement, de protéger les artefacts des modèles, d'assurer une surveillance continue et d'appliquer des contrôles d'accès stricts. Pour disposer d'une base solide, il est recommandé de se référer à des cadres de référence reconnus, tels que le SSDFdu NIST et les principes « Secure by Design »de la CISA, afin de bénéficier de conseils d'experts.
Articles de blog connexes
- La fin du purgatoire des projets pilotes : Faire passer l'IA de l'expérimentation à la norme d'entreprise.
- Le manuel du Directeur de l'IA : 5 priorités pour les 12 prochains mois.
- Guide Ultime pour les Organisations Prêtes pour l'IA
- Systèmes agentiques expliqués : Le passage des chatbots à l'action autonome.




