


AI models need quality data, but traditional methods can't keep up. Manual data collection is slow, expensive, and prone to errors, while privacy laws like GDPR and HIPAA add complexity. Synthetic data pipelines offer a solution by generating artificial datasets that mimic patterns in real data without privacy risks. These pipelines save time, cut costs, and improve AI performance. For example, companies like ING Belgium and GoDaddy have reduced data preparation time by up to 90% and avoided fines for data misuse. By 2028, synthetic data could make up 80% of AI training data, transforming industries like healthcare, finance, and autonomous vehicles.
Key Points:
- Data Challenges: Scarcity, privacy regulations, and high manual labeling costs.
- Synthetic Data Benefits: Faster generation, reduced costs (up to 99%), and improved privacy compliance.
- Real-World Examples: ING Belgium created 10,000 payment records in 2 minutes, improving system testing efficiency.
- Industries Impacted: Healthcare (rare disease research), finance (fraud detection), cybersecurity, and autonomous vehicles.
Synthetic pipelines are reshaping AI development, offering efficient, scalable solutions to data quality problems.
Building Synthetic Data Pipelines for Open Research and Scalable AI Development
sbb-itb-e314c3b
How Synthetic Data Pipelines Solve Quality Problems
Synthetic data pipelines are designed to generate artificial datasets that mimic real-world patterns while ensuring sensitive information remains protected. Unlike traditional data collection methods, these pipelines follow a structured, multi-step process that includes generation, validation, and refinement. Advanced techniques like GANs (Generative Adversarial Networks), VAEs (Variational Autoencoders), and large language models are often employed to create this data. Rigorous quality checks then verify statistical accuracy and compliance with privacy standards, ensuring the data is both reliable and secure [5][1]. Let’s break down how these pipelines work and the practical advantages they deliver.
What Are Synthetic Data Pipelines?
A synthetic data pipeline is an automated system that systematically produces artificial datasets through a controlled series of steps. The process begins with data generation, where algorithms analyze real-world patterns and generate new records that maintain statistical relationships. Following this, the validation phase measures how closely the synthetic data aligns with the original dataset. Ideally, the synthetic data should reflect the natural variance found between training and holdout sets [5].
The final stage is automated refinement, which includes three key types of filtering: basic quality checks, ensuring label consistency, and aligning data distribution. This structured approach directly tackles common data quality issues. For example, in 2023, MOSTLY AI applied this framework to the UCI Adult Income dataset (39,074 records). By splitting the data into training and holdout sets and measuring the Total Variational Distance, they achieved an average overall accuracy of 98.3% - with 98.9% univariate accuracy and 97.7% bivariate accuracy for the synthetic dataset [5]. This robust process not only guarantees statistical precision but also delivers practical, measurable outcomes.
Benefits of Using Synthetic Data
Synthetic data pipelines offer clear solutions to common data quality challenges, providing benefits that are both significant and measurable. One major advantage is their ability to address edge-case scarcity. Unlike manual labelling, which can be expensive and time-consuming [1], synthetic generation dramatically reduces costs. For instance, in January 2026, ING Belgium used the Synthetic Data Vault (SDV) to create 10,000 synthetic payment records in just 2 minutes. This approach increased test coverage for their SEPA payment processing system by 100 times, while requiring only a fraction of the manual effort previously needed [1].
Another key benefit is enhanced privacy compliance through the use of Differential Privacy (DP). Unlike traditional anonymisation techniques, DP-enabled pipelines provide mathematical guarantees of data de-identification, aligning with GDPR’s "Privacy by Design" principles [1]. Enterprise-grade solutions can achieve up to 97.8% accuracy in preserving statistical relationships while maintaining privacy protections [1]. This is particularly crucial given the financial risks of non-compliance - GDPR fines can exceed €20 million, and HIPAA breaches now average €10.4 million per incident [1].
Lastly, synthetic data pipelines accelerate development and significantly cut costs. Organisations leveraging synthetic data report cost reductions of up to 99% and a tenfold increase in model deployment speed [1]. By 2026, synthetic data is expected to account for 60% of all AI training data [1]. This combination of speed, affordability, and regulatory alignment makes synthetic pipelines an essential part of modern AI development.
Building a Synthetic Data Pipeline
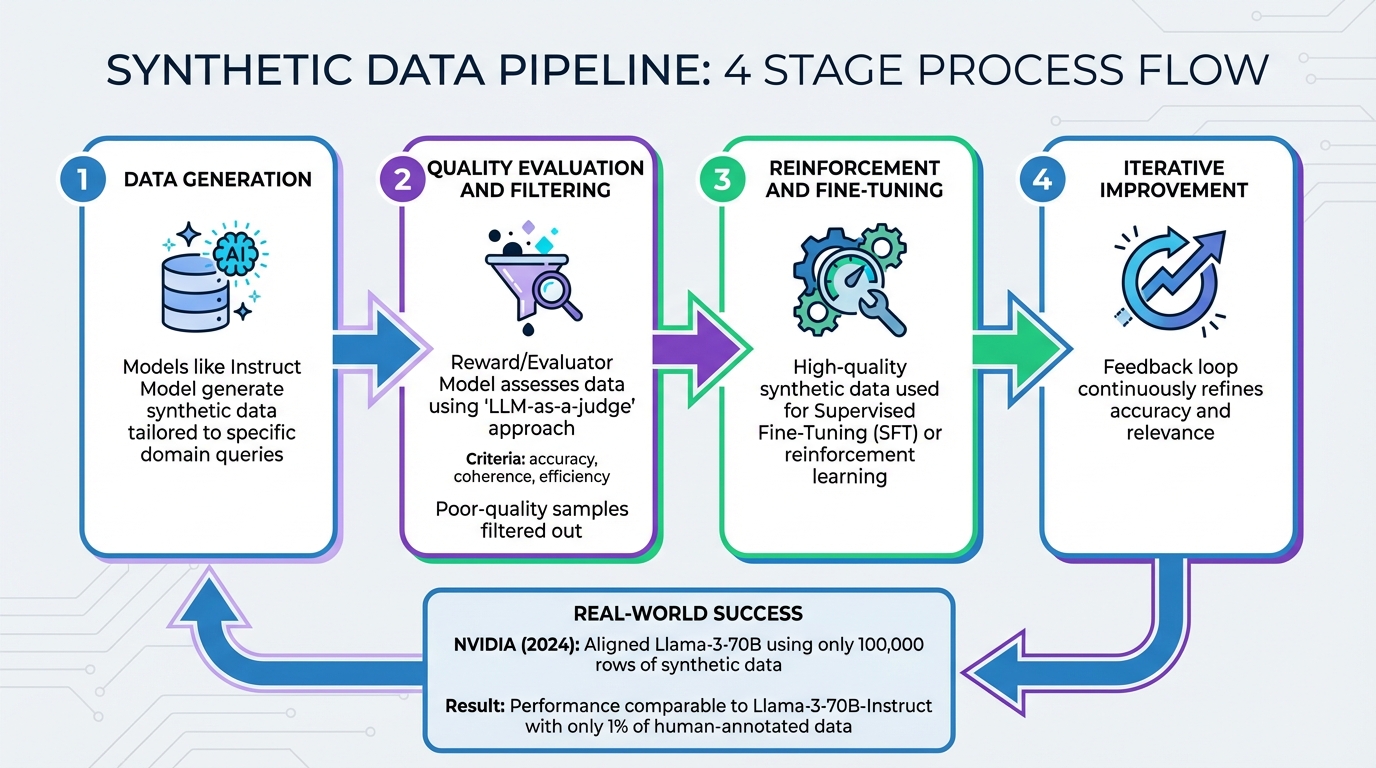
Four Stages of Building a Synthetic Data Pipeline
Creating a synthetic data pipeline allows you to turn the advantages of synthetic data into practical workflows. This process involves a series of interconnected stages, each playing a critical role in ensuring the pipeline's success. Let’s break down these stages and the technologies that can help you build a dependable system.
Main Stages of a Synthetic Data Pipeline
A well-structured pipeline typically includes four key stages:
- Data Generation: This is where synthetic data is created. Models like an Instruct Model are used to generate data tailored to specific domain queries [7].
- Quality Evaluation and Filtering: In this stage, a Reward or Evaluator Model assesses the synthetic data based on criteria like accuracy, coherence, and efficiency [6][7]. This approach, often referred to as "LLM-as-a-judge", automates the scoring and ranking of synthetic samples, eliminating the need for costly human annotation. Poor-quality samples are filtered out [6][7].
- Reinforcement and Fine-Tuning: High-quality synthetic data from the previous stage is used for Supervised Fine-Tuning (SFT) or reinforcement learning techniques to improve the model further.
- Iterative Improvement: This step introduces a feedback loop to continuously refine the accuracy and relevance of the synthetic data [6].
A remarkable example of this process in action comes from NVIDIA in 2024. They aligned their Llama-3-70B base model using just 100,000 rows of synthetic conversational data (dubbed the "Daring Anteater" dataset). This approach achieved performance comparable to Llama-3-70B-Instruct while relying on only 1% of the human-annotated data [7]. This demonstrates how a well-designed pipeline can significantly reduce the need for manual labeling without sacrificing performance.
Tools and Technologies You Can Use
The success of each stage relies heavily on choosing the right tools. Here’s a look at some of the options available:
-
Generation Technologies:
- Generative Adversarial Networks (GANs) are ideal for creating high-quality images.
- Variational Autoencoders (VAEs) are effective for stable anomaly detection.
- Large Language Models like Claude 3.7, Llama 3, and GPT-o3 excel in text and code generation.
- Diffusion models are gaining traction for producing high-quality visuals and refining structured data [4][11].
-
Pipeline Orchestration and Management:
- Apache Airflow and Dagster allow for automated scheduling and monitoring of workflows [10].
- Databricks Unity Catalog provides centralized governance for synthetic data and AI models.
- DreamFactory simplifies the creation of secure REST APIs to connect synthetic data sources to training environments without manual coding [4][9].
- CI/CD tools automate the provisioning of datasets for testing purposes [8].
When it comes to tools, you can choose between open-source and commercial options based on your needs:
- Open-source tools like SDV (Synthetic Data Vault), Apache Airflow, and Faker are free and excellent for research or prototyping [10][1].
- For enterprise-level requirements, solutions like Gretel Synthetics offer managed platforms with pricing ranging from €280 to over €9,500 per month. NVIDIA’s Nemotron-4 340B, available under a permissive license, is another strong option for commercial use [1][6].
Most successful implementations use a "Core-Expansion" strategy, blending 70–80% high-quality human-generated data with 20–30% synthetic data. This approach ensures accurate data distribution while covering edge cases [1].
"High-quality training data plays a critical role in the performance, accuracy and quality of responses from a custom LLM - but robust datasets can be prohibitively expensive and difficult to access." - NVIDIA [6]
Industry Applications and Case Studies
Synthetic Data in Healthcare, Finance, Cybersecurity, and Autonomous Vehicles
Synthetic data pipelines are making waves across industries by addressing critical challenges like data scarcity, privacy concerns, and dataset imbalances. Let’s take a closer look at how they’re being used:
In healthcare, synthetic data helps tackle the lack of information on rare diseases while safeguarding patient privacy. For instance, researchers in New Zealand used synthetic survey data to predict that GP visits for individuals aged 65+ could increase from 8.8 to 15.3 annually in high-morbidity scenarios. This insight aids in better resource allocation [14]. Additionally, synthetic data can reduce bias by oversampling underrepresented groups [13][14].
In the finance sector, synthetic data plays a key role in risk management, portfolio optimisation, and algorithmic trading, all while meeting strict privacy standards. By upsampling minority classes in imbalanced transactional datasets, financial institutions amplify the "fraud signal" in detection systems. This approach is particularly useful for addressing the rarity of property fraud cases, which often lack sufficient data to train effective AI models [17][18].
Cybersecurity benefits from synthetic data by balancing datasets for intrusion detection systems and generating adversarial inputs to test model safety. This automated "red-teaming" ensures robust security measures [13][15]. Meanwhile, in autonomous vehicle development, synthetic data pipelines reduce the need for labelled data by 90% while improving perception models’ performance under challenging conditions like extreme weather or poor lighting [16].
Performance Comparison: Baseline vs. Synthetic Data Models
The impact of synthetic data is evident in its ability to boost AI model performance. For example, in March 2024, Jianhao Yuan and colleagues achieved a 70.9% top-1 classification accuracy on ImageNet1K using only synthetic data. Scaling the synthetic pipeline tenfold pushed accuracy up to 76.0% [2]. Similarly, models trained with conditional synthetic chest CT scans for COVID-19 detection outperformed those trained on limited real-world datasets [14].
Here’s a breakdown of how synthetic data solves specific challenges across industries:
| Industry | Primary Use Case | Data Quality Challenge Solved |
|---|---|---|
| Healthcare | Diagnostic model training (e.g., COVID-19) | Data scarcity and patient privacy [14] |
| Finance | Fraud detection & Risk assessment | Regulatory compliance and diverse data types [12] |
| Cybersecurity | Intrusion detection & Red-teaming | Imbalanced datasets and adversarial testing [13][15] |
| Autonomous Vehicles | Perception model training | Extreme conditions and reduced need for labelled data [16] |
Marginal-based synthetic data generators, such as AIM and MWEM PGM, further enhance machine learning by delivering results nearly identical to those trained on real-world data [19]. Considering that up to 80% of AI development time is spent preparing real-world data [3], synthetic data pipelines are revolutionising how organisations approach model training. By addressing data quality constraints, they not only save time but also drive significant improvements in AI effectiveness.
How to Implement Synthetic Data Pipelines
Steps to Adopt Synthetic Data
Start by identifying the specific problem you're trying to solve. Are you dealing with edge cases, privacy concerns, or data imbalances? Clearly defining this will help you determine the scale and level of detail required, especially since manually labeling data can be expensive and time-consuming.
Begin with a Proof of Concept (PoC) using 1,000 to 10,000 non-sensitive records. Open-source tools like SDV are great for testing the quality of synthetic data before scaling up [1]. By mirroring the schema of your real-world data - while excluding unique identifiers - you can avoid overfitting and reduce privacy risks [20][21]. Synthetic data generation can save significant time and effort compared to manual methods.
When choosing methods, Gaussian Copulas are excellent for quick baselines, while GANs and VAEs are better suited for capturing complex relationships in tabular, text, or image data. Validate your synthetic data by running statistical tests against holdout sets [5]. Always split your data into training and holdout sets to prevent memorization [5]. This process can then feed directly into an automated feedback loop.
Automate feedback loops using tools like Python scripts or Airflow to evaluate the quality of the synthetic data. Samples that don’t meet quality standards can be automatically discarded [20]. For example, in February 2026, Paytient adopted Tonic.ai’s synthetic data system for processing sensitive health and payment data, which significantly improved their efficiency [24]. Similarly, Flywire replaced manual scripts with automated synthetic data generation, reducing the time to set up new test environments from 20 days to just minutes [24].
When moving to production, follow a "Crawl, Walk, Run" approach. Start small with manageable datasets and short training cycles (1 to 10 minutes). Gradually scale up to handle more complex, multi-table environments [22]. A hybrid approach often works best - combine 70–80% high-quality real data with 20–30% synthetic data. This ensures realism while covering edge cases [1]. Begin large-scale training with synthetic data and use real data for final fine-tuning to anchor your model in reality [23].
Best Practices for Maintaining Quality
Once your pipeline is up and running, maintaining data quality is crucial. Evaluate your synthetic data on three key dimensions: Fidelity (how closely it mirrors real-world data), Utility (its effectiveness in downstream machine learning tasks), and Privacy (ensuring it protects against re-identification). For production, aim for Privacy ≥85%, Utility ≥80%, and Fidelity ≥90%. Additionally, univariate matching should exceed 85%, bivariate trends should surpass 80%, and the singling-out risk should stay below 1% [1].
Maintain a "Gold Set" - a curated, high-quality dataset that serves as a benchmark for generating synthetic data [1]. Avoid over-tuning your models to the entire dataset. Instead, introduce randomness and noise to capture edge cases without simply replicating common patterns [21]. Incorporate Differential Privacy (DP) during training to meet GDPR and HIPAA compliance standards while providing mathematical assurances of de-identification [1].
"Synthetic data is not just an alternative but a core component for scalable AI development." – Nascenia [20]
As your production data evolves, version your generators and monitor for drift. Use MLOps platforms like Kubeflow or Airflow to automate the process of selecting the best synthesizer by running parallel evaluations of different models [1]. Tag metadata, ensure compatibility, and save validated data in formats like CSV or JSON to integrate seamlessly into your existing machine learning pipelines.
Conclusion: Solving AI's Data Quality Problem with Synthetic Pipelines
Synthetic data pipelines have become a cornerstone for advancing AI development. By 2028, an estimated 80% of AI training data will be synthetic, a dramatic rise from just 5% in 2021 [25]. This shift tackles some of AI's biggest hurdles: limited data availability, privacy concerns, bias, and the difficulty of safely addressing rare edge cases. The result? Major operational and cost-saving benefits.
Organisations adopting synthetic pipelines can slash costs by as much as 99% while speeding up model deployment by a factor of 10 [1]. For example, manually labelling a single edge case can cost €47,000, but synthetic data generation reduces that to just €470 [1]. A real-world example comes from GoDaddy, which in January 2026 reported cutting the time spent on test data creation by 90% and eliminating the need for production data in test environments entirely [26].
Synthetic data not only mitigates scarcity but frequently outperforms real data.
- Kalyan Veeramachaneni, Principal Research Scientist, MIT [25]
These advantages are being felt across diverse industries. In healthcare, synthetic pipelines enable rare disease research while safeguarding compliance with regulations like HIPAA. In finance, they allow institutions to test fraud detection systems using millions of synthetic transactions. Meanwhile, autonomous vehicle companies can simulate billions of miles of driving under conditions that would be impossible to replicate in the real world [25].
FAQs
How do synthetic data pipelines protect privacy while staying compliant with regulations?
Synthetic data pipelines play a crucial role in maintaining privacy compliance by employing advanced techniques to anonymize data and safeguard sensitive information. These pipelines create synthetic data that is decoupled from the original dataset, which helps minimize the chances of re-identification or privacy breaches.
One standout method is differential privacy, a mathematical framework that restricts how much information synthetic data can reveal about the original dataset. Other techniques, such as privacy masking and carefully designed synthesis rules, ensure that the generated data remains distinct from real data. These measures are crafted to comply with privacy laws like GDPR and HIPAA, enabling organizations to leverage high-quality data for AI training while staying within legal and ethical boundaries.
Which industries benefit the most from synthetic data pipelines?
Synthetic data pipelines are reshaping industries that grapple with issues like limited data availability, privacy restrictions, or the demand for varied datasets. Take healthcare and biomedical research, for example. These fields lean on synthetic data to safeguard patient privacy while advancing AI model training and research efforts.
In manufacturing, synthetic data plays a different but equally important role. It helps streamline operations, boost analytics capabilities, and cut down costs associated with collecting and labelling data.
Beyond these, sectors like finance, telecommunications, and public services also tap into synthetic data. It enables secure data sharing, helps reduce bias, and ensures compliance with privacy laws. These pipelines are a game-changer, allowing organisations to speed up AI development, enhance model precision, and extract valuable insights from sensitive or scarce datasets - all while meeting stringent privacy requirements.
How do synthetic data pipelines enhance the performance of AI models?
Synthetic data pipelines play a key role in boosting AI model performance by tackling issues such as limited data availability and bias. These pipelines create well-crafted, representative datasets that help improve model precision, consistency, and adaptability.
By mimicking a wide range of scenarios, these systems enable quicker training and testing processes, cutting down the reliance on expensive or hard-to-access real-world data. This approach ensures AI models are better prepared to manage real-world complexities, leading to more dependable predictions and results.




